TPU vs GPU Google ha la possibilità di superare la velocità di Nvidia.
TPU v4 è una soluzione hardware potente e flessibile per affrontare le sfide di scalabilità e prestazioni nei moderni carichi di lavoro di apprendimento automatico.


Google Supera NVidia con le sue nuove TPU di quarta generazione, un salto avanti nell'efficienza e nella potenza dell'Intelligenza Artificiale
Google ha recentemente presentato i suoi nuovi chip TPU v4 (Tensor Processing Unit), una generazione avanzata di processori specializzati progettati per accelerare la gestione e l'elaborazione dei carichi di lavoro nel campo del deep learning. Questi chip rivoluzionari sono già stati utilizzati per addestrare il modello generativo alla base del funzionamento del chatbot Bard, mostrando le loro incredibili capacità.
Le TPU sono state sviluppate da Google con l'intento specifico di ottimizzare l'esecuzione di algoritmi di apprendimento automatico, i quali richiedono una vasta quantità di operazioni matematiche su tensori - strutture dati multidimensionali fondamentali nel deep learning. Questi chip lavorano con il framework Google TensorFlow, ma possono anche essere integrati con altri strumenti, come PyTorch e MXNet. Google ha utilizzato le TPU per migliorare la performance di servizi quali Google Search, Google Photos, Google Assistant e molti altri.
Le TPU rientrano nella cosiddetta "Domain Specific Architecture" (DSA), un termine che Google usa per riferirsi a un insieme di architetture hardware personalizzate, progettate e implementate dall'azienda di Mountain View per gestire specifici carichi di lavoro nell'elaborazione dei dati. Le DSA mirano a migliorare le prestazioni e l'efficienza energetica dei servizi di Google tramite l'utilizzo di hardware specializzato, perfettamente adattato ai requisiti di elaborazione dei dati.
Nel loro ultimo documento, gli ingegneri di Google descrivono in dettaglio come la TPU v4, la più recente architettura DSA, viene utilizzata per creare supercomputer di nuova generazione destinati a gestire modelli avanzati. Questo include l'uso di switch a circuito ottico (OCS), che permettono di riconfigurare dinamicamente la topologia dell'interconnessione per migliorare scala, disponibilità, utilizzo, modularità, distribuzione, sicurezza, alimentazione e prestazioni.
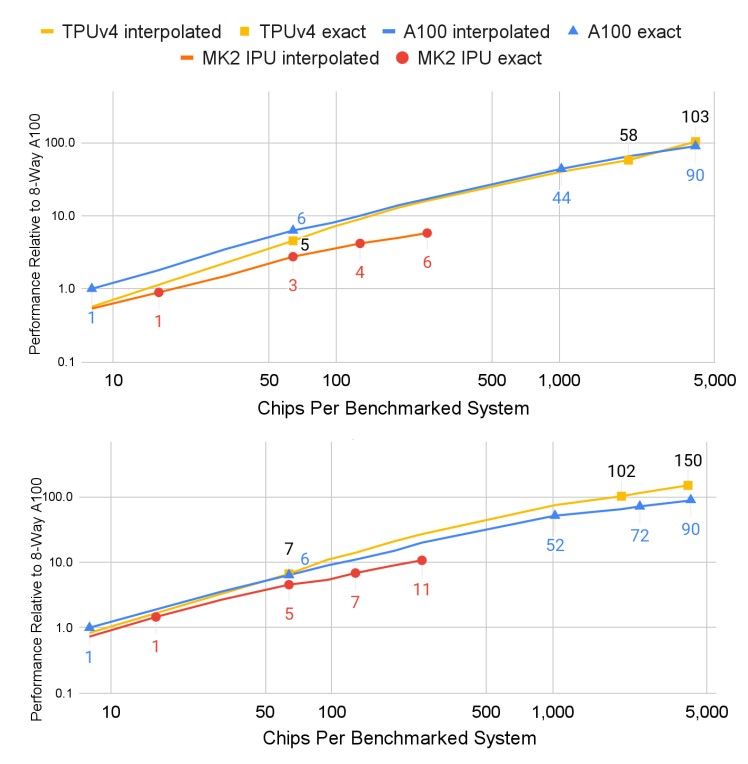
Le TPU v4 si distinguono per l'inclusione dei SparseCores, processori specializzati che accelerano i modelli utilizzando un approccio estremamente parsimonioso in termini di spazio occupato e potenza richiesta. Grazie a queste innovative caratteristiche, le TPU v4, secondo i tecnici di Google, risulterebbero fino a 1,7 volte più potenti e fino a 1,9 volte più efficienti dal punto di vista energetico rispetto alla NVidia A100.
Per confronto, la Nvidia A100 è una GPU di alto livello progettata per il machine learning, l'intelligenza artificiale e altre applicazioni di calcolo particolarmente esigenti. Questa GPU si basa sull'architettura Ampere di Nvidia, utilizza un processo di costruzione a 7 nanometri e possiede una memoria HBM2 (High Bandwidth Memory) con una capacità di diverse decine di gigabyte a seconda del modello.

Con l'introduzione delle nuove TPU di quarta generazione, Google sembra aver fatto un significativo passo avanti nell'ambito dell'Intelligenza Artificiale e del Machine Learning. L'introduzione degli SparseCores e l'uso innovativo degli switch a circuito ottico mostrano come Google stia cercando di superare i limiti delle tecnologie esistenti per offrire soluzioni sempre più efficienti e potenti. Nonostante la Nvidia A100 rimanga una soluzione di riferimento nel campo del calcolo ad alte prestazioni, le prestazioni dichiarate delle TPU v4 di Google suggeriscono che la competizione nel campo del deep learning e dell'Intelligenza Artificiale sta diventando sempre più intensa.
L'utilizzo delle TPU v4 per addestrare il modello generativo alla base del chatbot Bard è solo un esempio di come queste nuove tecnologie possano essere applicate. Mentre l'adozione di queste nuove TPU continua a crescere, è probabile che vedremo ulteriori progressi nel campo dell'apprendimento automatico e dell'intelligenza artificiale, con Google che continua a guidare la strada in termini di innovazione e sviluppo tecnologico.
Sarà interessante vedere come la crescente competizione tra Google e altri giganti tecnologici come Nvidia porterà ad ulteriori miglioramenti in questo settore. Ciò che è certo è che questi sviluppi tecnologici continueranno a trasformare il modo in cui interagiamo con le macchine e con il mondo digitale.

TPU v4: An Optically Reconfigurable Supercomputer for Machine Learning with Hardware Support for Embeddings
Ecco il riassunto di alcune informazioni tecniche contenute all'interno del documento pubblicato dagli ingegneri Google (Norman P. Jouppi, George Kurian, Sheng Li, Peter Ma, Rahul Nagarajan, Lifeng Nai, Nishant Patil, Suvinay Subramanian, Andy Swing, Brian Towles, Cliff Young, Xiang Zhou, Zongwei Zhou, and David Patterson - Google Mountain View CA) :
In risposta alle innovazioni nei modelli di apprendimento automatico (ML), i carichi di lavoro in produzione hanno subito cambiamenti radicali e rapidi. TPU v4 è la quinta architettura specifica del dominio (DSA) di Google e il suo terzo supercomputer per tali modelli ML. Gli switch a circuito ottico (OCSes) riconfigurano dinamicamente la sua topologia di interconnessione per migliorare scala, disponibilità, utilizzo, modularità, sicurezza, potenza e prestazioni. Gli utenti possono scegliere una topologia toro 3D distorta, se lo desiderano. Ogni TPU v4 include SparseCores, processori dataflow che accelerano i modelli basati su embeddings con un incremento del 5-7 volte ma utilizzando solo il 5% dell'area e della potenza del chip. Dal 2020, il TPU v4 supera il TPU v3 del 2,1 volte e migliora le prestazioni per watt del 2,7 volte. Il supercomputer TPU v4 è 4 volte più grande, con 4096 chip, e quindi quasi 10 volte più veloce complessivamente. Per sistemi di dimensioni simili, è circa 4,3-4,5 volte più veloce del Graphcore IPU Bow e 1,2-1,7 volte più veloce e usa 1,3-1,9 volte meno energia rispetto al Nvidia A100.
Per quanto riguarda gli architetti, i modelli di apprendimento automatico (ML) continuano ad evolvere in modi impegnativi, sia in termini di scala che di algoritmi. Esempi del primo caso sono i grandi modelli linguistici (LLM) e esempi del secondo sono gli embeddings necessari per i sistemi di raccomandazione (modelli di raccomandazione basati su deep learning o DLRM) e i calcoli enormi dei Transformers e BERT. L'incredibile scala degli recenti LLM ha esteso la scala del nostro supercomputer ML da 256 nodi TPU v2 a 4096 nodi TPU v4.
Questo documento descrive tre importanti funzionalità di TPU v4 che rispondono a queste sfide:
- Sono stati affrontati gli ostacoli di scala e affidabilità introducendo gli Optical Circuit Switches (OCSes) con collegamenti ottici di dati, consentendo un supercomputer da 4K nodi attraverso la riconfigurazione per tollerare 1K host CPU che non sono disponibili dallo 0,1% all'1,0% del tempo.
- Rivelare il supporto hardware per gli embeddings in DLRM (SparseCore o SC), parte dei TPU fin dalla versione TPU v2.
- Combinando le prime due capacità, gli embeddings aggiungono modelli di comunicazione all-to-all alle richieste su interconnessioni su scala di supercomputer. A differenza del all-reduce usato nella backpropagation, che si mappa bene su tori 2D e 3D, i modelli all-to-all sollecitano la larghezza di banda di bisezione. Gli OCSes permettono una flessibile configurazione della topologia, incluso il toro distorto, che ha migliori prestazioni su larga scala rispetto a un toro 3D perfetto.
Gli OCSes in TPU v4 sono l'innovazione chiave per affrontare le sfide di scalabilità e affidabilità. Essi consentono la creazione di un supercomputer di 4.096 nodi attraverso la riconfigurazione per tollerare 1.000 host CPU che non sono disponibili tra lo 0,1% e l'1,0% del tempo. Questa è una funzionalità importante perché permette un elevato grado di flessibilità nel configurare e ottimizzare i carichi di lavoro del supercomputer.
Il supporto hardware per gli embeddings in Deep Learning Recommendation Model (DLRM) è un altro importante aggiornamento di TPU v4. Questo viene fornito attraverso SparseCore o SC, che fa parte dei TPU dalla versione TPU v2. Questa funzionalità permette un miglioramento significativo delle prestazioni per i modelli di raccomandazione basati sul deep learning, che sono ampiamente utilizzati nei sistemi di raccomandazione moderni.
La combinazione di queste due capacità, cioè gli OCSes e il supporto per gli embeddings, permette di aggiungere modelli di comunicazione all-to-all alle richieste su interconnessioni a scala di supercomputer. Questi modelli sono diversi dall'all-reduce usato nella backpropagation, che si mappa bene su tori 2D e 3D. I modelli all-to-all, invece, richiedono una larghezza di banda di bisezione elevata. Gli OCSes permettono una configurazione flessibile della topologia, incluso il toroi distorto, che offre migliori prestazioni su larga scala rispetto a un toro 3D perfetto.
TPU v4 è una soluzione hardware potente e flessibile per affrontare le sfide di scalabilità e prestazioni nei moderni carichi di lavoro di apprendimento automatico. Con il suo supporto per gli embeddings e la sua capacità di riconfigurare dinamicamente la topologia di interconnessione, offre un'enorme promessa per l'accelerazione dell'apprendimento automatico a livello di supercomputer.