PyTorch Supercharging Training con float8 e FSDP2


PyTorch ha dimostrato che è possibile ottenere fino al 50% di aumento del throughput, mantenendo la parità di perdita e benchmark di valutazione rispetto all'allenamento con FSDP1 in formato bf16. Questo risultato è stato raggiunto grazie all'utilizzo di FSDP2, DTensor e torch.compile, combinati con l'implementazione float8 di torchao, sia per gli aggiornamenti lineari (compute) che per la comunicazione dei pesi (all_gather in float8). Le ottimizzazioni sono state applicate a diversi modelli Meta LLaMa, dalle dimensioni più piccole (1,8 miliardi di parametri) fino a modelli da 405 miliardi, rendendo l'allenamento più rapido che mai.
L'approccio di PyTorch si basa sull'integrazione di tecnologie avanzate e nuove metodologie per affrontare le sfide dell'addestramento su larga scala. FSDP2 è stato utilizzato per ottimizzare la memoria e migliorare l'efficienza dei modelli, mentre DTensor ha reso possibile una gestione più efficiente dei dati distribuiti. Inoltre, torch.compile ha svolto un ruolo fondamentale nella generazione di codice altamente ottimizzato, massimizzando le prestazioni del sistema.
Miglioramenti con Meta Llama3
PyTorch ha utilizzato l'architettura Meta Llama3 per dimostrare questi miglioramenti, effettuando studi di qualità del modello su due scale: 100 miliardi di token per un modello da 8 miliardi di parametri e 50 miliardi di token per un modello da 70 miliardi di parametri. Questi studi mostrano che le curve di perdita durante l'allenamento con float8 sono identiche a quelle con bf16. Questo significa che l'addestramento in float8 non sacrifica la qualità del modello, ma piuttosto offre un notevole miglioramento in termini di efficienza e velocità. Inoltre, è stato addestrato un modello da 3 miliardi di parametri fino a 1 trilione di token utilizzando il dataset FineWeb-edu, eseguendo benchmark di valutazione standard per verificare che la qualità del modello sia paragonabile a quella di un allenamento bf16.
Durante questi esperimenti, è stata osservata una significativa riduzione del tempo di addestramento necessario per ottenere risultati simili rispetto al formato bf16. Questo è particolarmente importante quando si addestrano modelli di grandi dimensioni, come i modelli LLaMa con decine di miliardi di parametri. Grazie all'integrazione di float8, PyTorch è stato in grado di dimostrare che è possibile addestrare modelli di qualità elevata in meno tempo, consentendo quindi una più rapida iterazione e un maggior numero di esperimenti nello stesso arco di tempo.
Cos'è Float8?
Il formato float8 per l'addestramento dei modelli è stato introdotto da NVIDIA, ARM e Intel nel 2022, dimostrando che è possibile utilizzare una precisione ridotta senza compromettere la qualità del modello. Con l'avvento delle nuove GPU, come la serie NVIDIA Hopper, l'addestramento in formato FP8 è diventato fattibile, promettendo un miglioramento del throughput di oltre il doppio grazie al supporto nativo del core tensoriale float8. Tuttavia, restano alcune sfide da affrontare per sfruttare appieno questo potenziale:
- Abilitare le operazioni principali del modello, come matmul e attenzione, in float8;
- Abilitare l'addestramento float8 in un framework distribuito;
- Abilitare la comunicazione dei pesi tra GPU in float8.
Le operazioni matmul in float8 sono state abilitate dalle librerie NVIDIA, mentre le altre due sfide sono state risolte con gli aggiornamenti recenti a FSDP2 e torchao. Questo ha portato a un miglioramento della scalabilità dei modelli addestrati in float8, rendendo possibile l'uso di questo formato in ambienti distribuiti su larga scala, come nei grandi cluster di GPU.
L'uso di float8 è particolarmente vantaggioso quando si tratta di addestrare modelli molto grandi, dove la comunicazione dei pesi tra le GPU può diventare un collo di bottiglia significativo. Con float8, il trasferimento dei pesi avviene più velocemente, migliorando così l'efficienza complessiva dell'addestramento. Inoltre, grazie a tecniche come la tensor scaling, è possibile mantenere la stabilità numerica durante le operazioni matematiche più delicate.
Esperimenti e Risultati
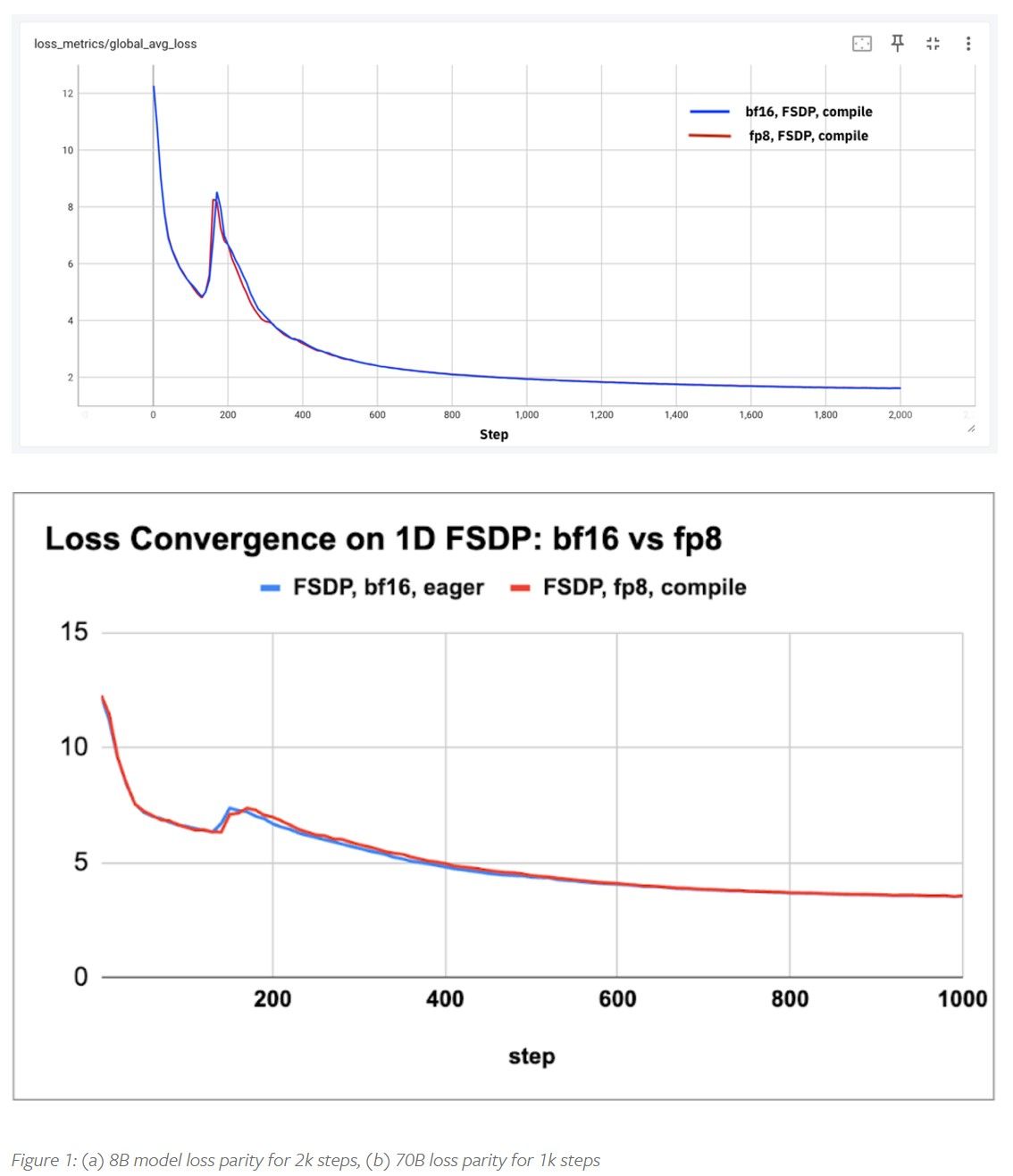
Per dimostrare i benefici dell'allenamento in float8, PyTorch ha effettuato diversi esperimenti. Il primo è stato volto a verificare che la qualità del modello non venisse compromessa. A tal fine, sono stati addestrati modelli da 8 e 70 miliardi di parametri per alcune migliaia di passaggi e sono state confrontate le curve di perdita tra float8 e bf16. Gli esperimenti sono stati condotti su tre diversi cluster H100, ciascuno con 128, 256 e 512 GPU H100, per garantire la riproducibilità dei risultati.
I risultati mostrano che, su scale ridotte di token, float8 raggiunge la stessa parità di perdita di bf16. Questo significa che anche se si utilizza una precisione ridotta, non si osserva alcuna perdita di qualità nelle prestazioni del modello. Successivamente, sono stati caratterizzati i guadagni in throughput per quattro diverse dimensioni di modello, da 1,8 miliardi a 405 miliardi di parametri. I guadagni osservati sono stati più significativi per i modelli più grandi (70B e 405B), con incrementi del throughput fino al 50%.
| Dimensione Modello | wps (bf16) | wps (float8) | Guadagno Percentuale |
|---|---|---|---|
| 1,8B | 29K | 35K | 18% |
| 8B | 8K | 10K | 28% |
| 70B | 956 | 1430 | 50% |
| 405B (TP4) | 149 | 227 | 52% |
Gli esperimenti dimostrano che i vantaggi dell'utilizzo del formato float8 diventano ancora più pronunciati con l'aumentare della dimensione del modello. Ciò significa che, man mano che si addestrano modelli più grandi, l'efficienza di float8 consente di ridurre notevolmente il tempo di addestramento e di utilizzare in modo più efficiente le risorse di calcolo disponibili. Questo è cruciale per la ricerca nel campo dell'intelligenza artificiale, dove i modelli diventano sempre più complessi e richiedono sempre maggiori risorse.
PyTorch ha anche addestrato un modello da 3 miliardi di parametri per 1 trilione di token utilizzando il dataset FineWeb-edu di Hugging Face, ottenendo valutazioni comparabili tra float8 e bf16. Ad esempio, mentre alcune metriche, come MMLU, mostrano un leggero vantaggio per bf16, ci si aspetta che questo divario diminuisca con l'ottimizzazione dei parametri di iper-taratura. In effetti, una parte significativa delle differenze osservate può essere attribuita a variazioni nei parametri di addestramento, come la dimensione del batch, che ha un impatto diretto sui risultati della valutazione.
| Benchmark | Score (float8) | Score (bf16) |
|---|---|---|
| MMLU (5-shot) | 0,26 | 0,29 |
| ARC-e | 0,73 | 0,73 |
| ARC-c | 0,43 | 0,46 |
| Hellaswag | 0,65 | 0,67 |
| sciq | 0,89 | 0,88 |
| OpenBook QA | 0,43 | 0,43 |
| PIQA | 0,76 | 0,76 |
| Winogrande | 0,60 | 0,65 |
| Media | 0,59 | 0,60 |
Il futuro di PyTorch
PyTorch sta attualmente lavorando alla valutazione di altre forme di parallelismo, come il parallelismo di contesto. L'obiettivo è dimostrare la composabilità e la capacità di fare scelte per l'addestramento di modelli su larga scala. Il parallelismo di contesto potrebbe offrire un ulteriore livello di ottimizzazione, consentendo a diverse parti del modello di essere elaborate contemporaneamente, migliorando ulteriormente la velocità complessiva di addestramento.
Inoltre, PyTorch sta esplorando l'integrazione di nuove tecniche di ottimizzazione dell'addestramento, come l'uso di diverse granularità di scalatura per float8, al fine di garantire la stabilità e migliorare l'efficienza. Questo tipo di lavoro di ricerca contribuirà a rendere l'addestramento di modelli su larga scala sempre più accessibile e alla portata di più sviluppatori e ricercatori, riducendo i costi associati e migliorando il ritorno sull'investimento in termini di risorse computazionali.
Si ringrazia Davis Wertheimer di IBM Research per il suo contributo nell'abilitazione del data loader per i training con torchtitan e IBM Cloud per l'accesso anticipato al cluster H100. Queste collaborazioni sono essenziali per portare avanti la ricerca e l'innovazione nel campo dell'intelligenza artificiale, consentendo esperimenti su larga scala e contribuendo allo sviluppo di nuove tecnologie per l'addestramento dei modelli.