OpenVINO: Decifrare la Postura del Tennis con Intelligenza Artificiale


Scopri come l'IA può rivoluzionare il mondo del tennis, analizzando in dettaglio la postura dei giocatori. Grazie ad OpenVINO, l'applicazione fornisce feedback preziosi sugli stili e le tecniche, portando l'allenamento al livello successivo.
In questo momento si tratta di una versione di base, solo al fine di provare l'efficienza di alcune tecnologie. Per una questione didattica analizziamo soltanto alcuni comportamenti e tiri effettuati dal tennista.
Nel tennis, ogni dettaglio conta. Mentre gli allenatori cercano ogni vantaggio possibile, la tecnologia emerge come un alleato essenziale nel fornire informazioni preziose. Non si tratta solo di racchette più avanzate o scarpe da ginnastica più leggere, ma anche di come l'IA può aiutare a decifrare le sfumature del movimento umano. La nostra applicazione, sostenuta dalla potenza di OpenVINO, mira a fare proprio questo: analizzare la postura di un giocatore di tennis, offrendo informazioni dettagliate sulle loro tecniche e movimenti.

Obiettivo dell'Applicazione
Il tennis, come molti altri sport, dipende in gran parte dalla tecnica. Una corretta postura e movimento possono fare la differenza tra un colpo vincente e uno fallito. L'obiettivo principale di questa applicazione è identificare e analizzare la postura di un giocatore durante una partita o una sessione di allenamento. Questo può aiutare gli allenatori a offrire feedback specifici e mirati, aiutando i giocatori a perfezionare le loro tecniche.
L'applicazione non si limita solo a riconoscere la postura; va oltre, cercando di identificare azioni specifiche come un servizio. Ciò fornisce un ulteriore livello di dettaglio, permettendo una migliore comprensione del gioco di un atleta.
Come Funziona?
Il cuore di questa applicazione risiede nella sua capacità di elaborare e analizzare immagini utilizzando una rete neurale profonda. Questo viene fatto attraverso OpenVINO, una piattaforma fornita da Intel che accelera le operazioni di inferenza di reti neurali profonde.
Dopo aver caricato un'immagine del giocatore, l'applicazione procede con una serie di passaggi:
- Preprocessamento: Adatta l'immagine alle dimensioni richieste dalla rete neurale.
- Inferenza: Analizza l'immagine per identificare i punti chiave della postura umana.
- Post-elaborazione: Traduce i risultati dell'inferenza in informazioni comprensibili, come la posizione dei vari arti e la relazione tra di loro.
- Analisi: Basandosi sui punti chiave rilevati, l'applicazione può inferire azioni specifiche, come se un giocatore sta eseguendo un servizio.
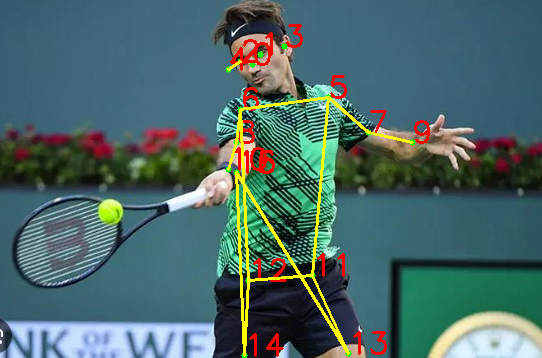
Ecco il codice utilizzato
Viene utilizzato Python 3.8 con OpenVino
import cv2
import numpy as np
from openvino.inference_engine import IECore
from IPython.display import display, Image
from PIL import Image
model_path = "raw_models/intel/human-pose-estimation-0005/FP16/human-pose-estimation-0005"
ie = IECore()
net = ie.read_network(model=model_path + ".xml", weights=model_path + ".bin")
exec_net = ie.load_network(network=net, device_name="CPU")
def preprocess_image(image_path, input_shape):
image = cv2.imread(image_path)
height, width, _ = image.shape
resized_image = cv2.resize(image, (input_shape[3], input_shape[2]))
input_image = np.transpose(resized_image, (2, 0, 1))
input_image = np.expand_dims(input_image, 0)
return image, input_image
input_shape = net.input_info["image"].tensor_desc.dims
image, input_image = preprocess_image("foto/dritto.jpg", input_shape)
# Esegui l'inferenza sul tuo modello.
results = exec_net.infer(inputs={"image": input_image})
# Connessioni tra i keypoints basate sull'ordine standard di OpenPose:
scheletro = [
(4, 2), # occhi testa
(9, 7), (7, 5), (5, 6), # Braccio sinistro
(10, 8), (8, 6), # Braccio destro
(11, 13), (13, 15), # Gamba sinistra
(12, 14), (14, 16), # Gamba destra
(12, 11), # Bacino
(12, 6), # Fianco destro
(5, 11), # fianco sinistro
]
# Visualizzazione dei keypoints:
# Ogni keypoint ha una coppia (x, y) sulla tua immagine.
print(results.keys())
heatmaps = results['heatmaps'][0] # Prendiamo il primo batch, assumendo un batch size di 1
# Estraiamo la posizione dei keypoints dalle mappe di calore
keypoints = []
for heatmap in heatmaps:
_, _, loc, _ = cv2.minMaxLoc(heatmap) # Questo restituisce la posizione del valore massimo nel heatmap
x, y = loc
keypoints.append((x, y))
# Ottieni le dimensioni dell'immagine
height, width, _ = image.shape
print(heatmaps.shape)
# Visualizziamo i keypoints sull'immagine
for idx, (x, y) in enumerate(keypoints):
cv2.circle(image, (int(x * width / heatmaps.shape[2]), int(y * height / heatmaps.shape[1])), 3, (0, 255, 0), -1)
cv2.putText(image, str(idx), (int(x * width / heatmaps.shape[2]), int(y * height / heatmaps.shape[1])), cv2.FONT_HERSHEY_SIMPLEX, 1, (0, 0, 255), 2)
# Visualizziamo scheletro
for (start, end) in scheletro:
start_point = (int(keypoints[start][0] * width / heatmaps.shape[2]), int(keypoints[start][1] * height / heatmaps.shape[1]))
end_point = (int(keypoints[end][0] * width / heatmaps.shape[2]), int(keypoints[end][1] * height / heatmaps.shape[1]))
cv2.line(image, start_point, end_point, (0, 255, 255), 2) # colore giallo e spessore 2
# Converti l'immagine di OpenCV in un formato compatibile con PIL e poi mostra l'immagine
pil_image = Image.fromarray(cv2.cvtColor(image, cv2.COLOR_BGR2RGB))
display(pil_image)
# Supponiamo che tu abbia già estratto i keypoints come mostrato in precedenza
torso_center = ((keypoints[8][0] + keypoints[7][0]) / 2, (keypoints[8][1] + keypoints[7][1]) / 2)
distance_right_arm = abs(keypoints[10][0] - torso_center[0])
distance_left_arm = abs(keypoints[9][0] - torso_center[0])
if distance_right_arm < distance_left_arm:
print("Dritto")
else:
print("Rovescio")
def is_serving(keypoints):
# Estraiamo le coordinate dei keypoints di interesse
right_shoulder = keypoints[6]
right_elbow = keypoints[8]
right_wrist = keypoints[10]
left_shoulder = keypoints[5]
left_elbow = keypoints[7]
left_wrist = keypoints[9]
right_hip = keypoints[12]
right_knee = keypoints[14]
# Condizioni che indicano un possibile servizio:
# 1. Il polso destro è più alto del gomito destro e della spalla destra
# 2. La palla (assunta vicino al polso sinistro) è sotto il gomito sinistro
# 3. L'anca destra è leggermente più alta del ginocchio destro (indicando una leggera piega nella preparazione)
if (right_wrist[1] < right_elbow[1] and right_wrist[1] < right_shoulder[1] and
left_wrist[1] > left_elbow[1] and
right_hip[1] < right_knee[1]):
return True
return False
# Usiamo la funzione per determinare se il giocatore sta effettuando un servizio
if is_serving(keypoints):
print("Il giocatore sta effettuando un servizio.")
else:
# Puoi estendere quest'altro ramo per altri colpi o azioni se necessario
print("Non è un servizio.")
cv2 (OpenCV)
Open Source Computer Vision Library è una delle librerie più popolari e complete per la computer vision. È scritta in C e C++ ed è disponibile per vari linguaggi di programmazione, inclusa Python.
Nel tuo script, cv2 viene utilizzato per diverse operazioni legate all'elaborazione delle immagini, come leggere un'immagine, ridimensionarla, disegnare cerchi (per i keypoints) e linee (per lo scheletro) sull'immagine e altre funzioni di visualizzazione.
numpy (np)
Numpy è una libreria fondamentale per l'elaborazione scientifica in Python. Offre supporto per lavorare con vettori e matrici di grandi dimensioni e fornisce una vasta collezione di funzioni matematiche per operare su questi array.
Nel contesto del tuo script, numpy viene utilizzato per manipolare e gestire i dati dell'immagine sotto forma di array multidimensionali. Ad esempio, viene utilizzato per trasporre e ridimensionare i dati dell'immagine.
openvino.inference_engine
OpenVINO (Open Visual Inference & Neural Network Optimization) è una piattaforma di Intel per accelerare l'inferenza delle reti neurali. Consente di eseguire modelli di deep learning ottimizzati su vari dispositivi, come CPU, GPU, FPGA e VPU.
All'interno del tuo script, usi IECore da openvino.inference_engine per inizializzare il core di inferenza. Questo ti permette di caricare il tuo modello di rete neurale e di eseguire inferenze su di esso, ottenendo risultati come i keypoints della postura umana dall'immagine fornita.
IPython.display e PIL (Python Imaging Library)
IPython.display è una funzionalità fornita dal pacchetto IPython (estensione di Python utilizzata principalmente per Jupyter Notebook) che aiuta a visualizzare vari formati di output direttamente nel notebook.
PIL (Python Imaging Library), ora noto come Pillow, è una libreria per aprire, manipolare e salvare molte diverse formati di file di immagine.
Usi display da IPython.display per mostrare l'immagine all'interno del notebook. Inoltre, converti l'immagine di OpenCV (in formato BGR) in un formato compatibile con PIL (RGB) usando Image da PIL, che permette poi di visualizzarla correttamente.
Queste librerie e piattaforme forniscono una potente combinazione di strumenti per l'elaborazione delle immagini e l'inferenza di modelli di deep learning, consentendoti di analizzare e visualizzare dettagliatamente la postura del tennis in un'immagine fornita.
Human-Pose-Estimation-0005
La scelta di questo modello specifico e l'uso della piattaforma OpenVINO permettono di ottenere risultati accurati e tempi di inferenza rapidi, essenziali per applicazioni che richiedono feedback immediato come l'analisi della tecnica nel tennis.
Questo modello è progettato per stimare la postura umana, ovvero la posizione di vari punti (o "keypoints") del corpo, come occhi, orecchie, gomiti, ginocchia, ecc., a partire da un'immagine o da un video. La stima della postura è fondamentale in molte applicazioni come l'analisi dello sport, l'interazione uomo-macchina, la realtà aumentata, ecc.
Caratteristiche:
- Precisione (FP16): La sigla "FP16" indica che il modello utilizza una precisione a virgola mobile a 16 bit. Questo bilancia la velocità e la precisione, permettendo inferenze più rapide rispetto alla precisione FP32 mantenendo al contempo un'accuratezza ragionevole.
- Keypoints: Il modello è in grado di identificare vari keypoints del corpo umano. Nel tuo script, si nota che il modello identifica e utilizza questi keypoints per tracciare segmenti tra di loro e formare una rappresentazione scheletrica del corpo.
Performance:
Grazie all'ottimizzazione per OpenVINO, il modello può raggiungere tempi di inferenza molto brevi, rendendolo ideale per applicazioni in tempo reale o che richiedono una rapida elaborazione di molte immagini.
Nello script, il modello viene caricato e utilizzato per eseguire inferenze sull'immagine fornita. I risultati dell'inferenza sono poi utilizzati per tracciare i keypoints e lo scheletro sulla persona nell'immagine.

Utilizzo della fonte video per analizzare alcune posizioni del tennista mediante OpenVino
L'analisi del movimento umano ha un ruolo fondamentale nel migliorare le prestazioni atletiche, specialmente in sport complessi come il tennis. La capacità di riconoscere e valutare automaticamente pose specifiche durante una partita può offrire spunti preziosi ai giocatori e ai loro allenatori.
Nel contesto del tennis, uno dei movimenti più tecnici e cruciali ad esempio è il servizio. Utilizzando il modello di stima della posa umana, human-pose-estimation-0005, è possibile analizzare ogni frame di una sequenza video e identificare con precisione la posizione delle articolazioni del giocatore.
Questo codice che propongo in questa pagina non risulta ancora completo e preciso ma può essere la base di partenza per un'elaborazione più complessa.
Ogni frame viene adeguatamente preelaborato attraverso la funzione preprocess_frame, l'immagine risultante viene inviata al modello per l'inferenza. Da qui, i risultati ottenuti rivelano i cosiddetti "punti chiave" o articolazioni del corpo.
Questi punti chiave non sono solo marker visivi. Sono le fondamenta su cui si basa la funzione is_serving per determinare se il giocatore sta effettuando un servizio. La logica sottostante considera la posizione relativa di diverse articolazioni, come il polso, il gomito e la spalla, per concludere se il movimento osservato corrisponde a un servizio.
Mentre la sequenza video viene analizzata, ogni frame viene arricchito con informazioni visive, evidenziando le articolazioni e tracciando le connessioni tra di loro. Questo offre una visualizzazione chiara e dettagliata dei movimenti del giocatore. Inoltre, la funzione di analisi del servizio permette di segnalare in tempo reale se un giocatore sta servendo, fornendo un feedback immediato sulla sequenza in corso.
import cv2
import numpy as np
from openvino.inference_engine import IECore
import matplotlib.pyplot as plt
from IPython.display import clear_output
# Modello e configurazione
model_path = "raw_models/intel/human-pose-estimation-0005/FP16/human-pose-estimation-0005"
ie = IECore()
net = ie.read_network(model=model_path + ".xml", weights=model_path + ".bin")
exec_net = ie.load_network(network=net, device_name="CPU")
input_shape = net.input_info["image"].tensor_desc.dims
# Connessioni tra i keypoints
scheletro = [
(4, 2), # occhi testa
(9, 7), (7, 5), (5, 6), # Braccio sinistro
(10, 8), (8, 6), # Braccio destro
(11, 13), (13, 15), # Gamba sinistra
(12, 14), (14, 16), # Gamba destra
(12, 11), # Bacino
(12, 6), # Fianco destro
(5, 11), # fianco sinistro
]
def preprocess_frame(frame, input_shape):
height, width, _ = frame.shape
resized_frame = cv2.resize(frame, (input_shape[3], input_shape[2]))
input_frame = np.transpose(resized_frame, (2, 0, 1))
input_frame = np.expand_dims(input_frame, 0)
return frame, input_frame
def is_serving(keypoints):
right_shoulder = keypoints[6]
right_elbow = keypoints[8]
right_wrist = keypoints[10]
left_shoulder = keypoints[5]
left_elbow = keypoints[7]
left_wrist = keypoints[9]
right_hip = keypoints[12]
right_knee = keypoints[14]
if (right_wrist[1] < right_elbow[1] and right_wrist[1] < right_shoulder[1] and
left_wrist[1] > left_elbow[1] and
right_hip[1] < right_knee[1]):
return True
return False
cap = cv2.VideoCapture('video/tennis4.mp4')
fourcc = cv2.VideoWriter_fourcc(*'XVID')
out = cv2.VideoWriter('output.avi', fourcc, 20.0, (int(cap.get(3)), int(cap.get(4))))
frame_count = 0
MAX_FRAMES = 100
while cap.isOpened() and frame_count < MAX_FRAMES:
ret, frame = cap.read()
frame_count += 1
if not ret:
break
frame, input_frame = preprocess_frame(frame, input_shape)
results = exec_net.infer(inputs={"image": input_frame})
heatmaps = results['heatmaps'][0]
keypoints = []
for heatmap in heatmaps:
_, _, loc, _ = cv2.minMaxLoc(heatmap)
x, y = loc
keypoints.append((x, y))
height, width, _ = frame.shape
for idx, (x, y) in enumerate(keypoints):
cv2.circle(frame, (int(x * width / heatmaps.shape[2]), int(y * height / heatmaps.shape[1])), 3, (0, 255, 0), -1)
cv2.putText(frame, str(idx), (int(x * width / heatmaps.shape[2]), int(y * height / heatmaps.shape[1])), cv2.FONT_HERSHEY_SIMPLEX, 1, (0, 0, 255), 2)
for (start, end) in scheletro:
start_point = (int(keypoints[start][0] * width / heatmaps.shape[2]), int(keypoints[start][1] * height / heatmaps.shape[1]))
end_point = (int(keypoints[end][0] * width / heatmaps.shape[2]), int(keypoints[end][1] * height / heatmaps.shape[1]))
cv2.line(frame, start_point, end_point, (0, 255, 255), 2)
# Analisi del movimento
if is_serving(keypoints):
cv2.putText(frame, "Servizio", (10, 60), cv2.FONT_HERSHEY_SIMPLEX, 1, (0, 0, 255), 2)
else:
cv2.putText(frame, "Analisi Servizio", (10, 60), cv2.FONT_HERSHEY_SIMPLEX, 1, (0, 0, 255), 2)
out.write(frame)
# Visualizzazione nel Jupyter Notebook
clear_output(wait=True)
plt.imshow(cv2.cvtColor(frame, cv2.COLOR_BGR2RGB))
plt.axis('off')
plt.show()
cap.release()
out.release()
cv2.destroyAllWindows()