Nvidia GPU Blackwell AI di nuova generazione


La nuova architettura GPU Blackwell di NVIDIA, che sarà svelata al GTC 2024, si prospetta come una rivoluzione nel campo dell'intelligenza artificiale e del calcolo ad alte prestazioni. Rispetto ai suoi predecessori, come l'A100 basato su Ampere e l'H100 di Hopper, Blackwell promette miglioramenti significativi sia in termini di prestazioni che di efficienza energetica.
La chiave di questa evoluzione risiede nell'adozione della tecnologia MCM (Multi-Chip Module), che consente l'impiego di più chiplet in un unico package, aumentando così in modo esponenziale le risorse e le prestazioni complessive. Inoltre, l'utilizzo del processo produttivo N3 per i chiplet con i CUDA core, contribuisce a questa escalation di potenza.
Le aspettative sono elevate anche per l'acceleratore B100, che potrebbe caratterizzarsi per un consumo energetico fino a 1000W, superiore ai 700W del suo predecessore H100, e l'utilizzo di memoria HBM più veloce. Questi miglioramenti dovrebbero garantire un salto prestazionale senza precedenti nella storia degli acceleratori NVIDIA.

Le GPU Blackwell AI sono descritte come un balzo avanti significativo nel settore dell'AI, con un focus particolare sulle prestazioni e sulle capacità di memoria. Si prevede che l'acceleratore includa memoria HBM3e, con capacità potenzialmente più elevate e specifiche aggiornate, oltre a ulteriori sviluppi nella piattaforma CUDA di NVIDIA, cruciale per le prestazioni AI.
NVIDIA sta per aprire un nuovo capitolo entusiasmante con la sua architettura Blackwell, che promette di riscrivere le regole del gioco in termini di prestazioni e capacità di elaborazione AI. L'attesa per l'evento GTC 2024 è palpabile, con l'industria che si prepara ad accogliere questa nuova era della tecnologia delle GPU.

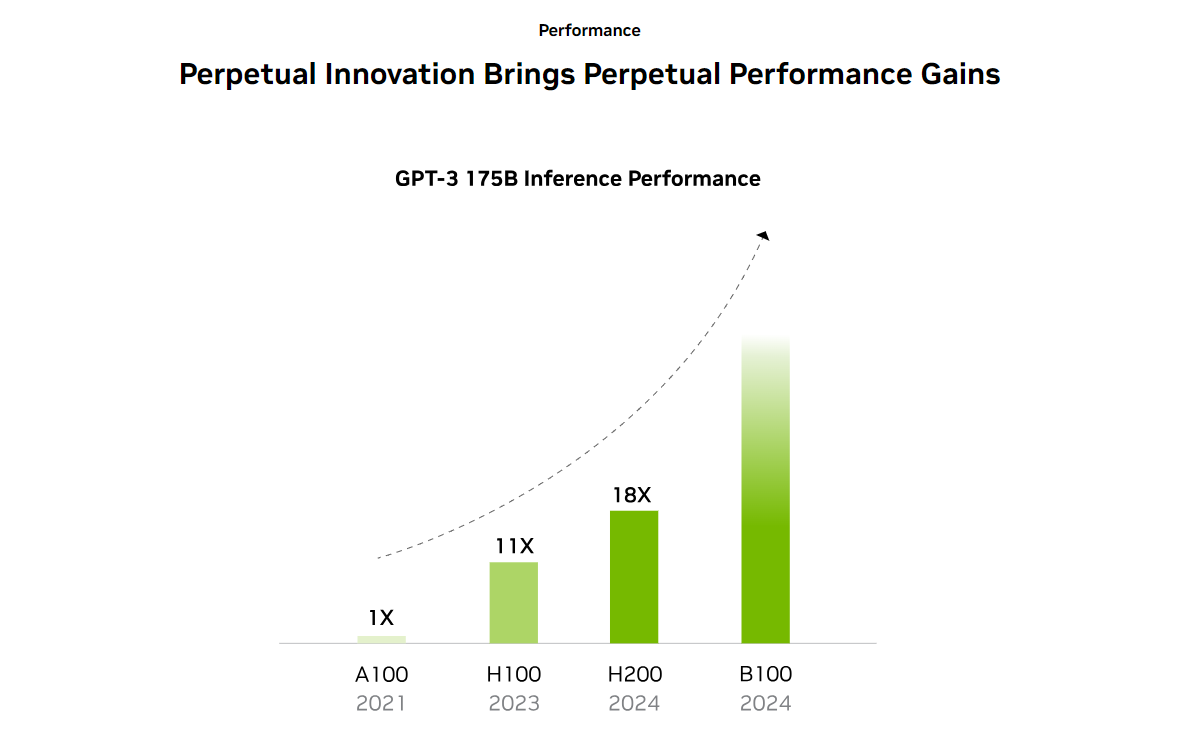
NVIDIA H200 Tensor Core GPU: Ha Rivoluzionare il Carico di lavoro nell'IA e nell'HPC,cosa dobbiamo aspettarci con all'arrivo di B100?
La GPU NVIDIA H200 Tensor Core, basata sull'architettura NVIDIA Hopper™, rappresenta un passo avanti significativo nel mondo dell'Intelligenza Artificiale (IA) e del Computing ad Alte Prestazioni (HPC). Progettata per potenziare l'IA generativa e i carichi di lavoro HPC, la H200 segna un progresso notevole in termini di prestazioni e capacità di memoria.
Memoria e Prestazioni Senza Precedenti
La H200 si distingue per i suoi 141 gigabyte (GB) di memoria HBM3e e una notevole larghezza di banda di memoria di 4.8 terabyte al secondo (TB/s). Questa configurazione raddoppia quasi la capacità del suo predecessore, la GPU NVIDIA H100 Tensor Core, e offre 1,4 volte più larghezza di banda della memoria. Questi miglioramenti sono cruciali per accelerare l'IA generativa, i grandi modelli linguistici e il calcolo scientifico, contribuendo a una maggiore efficienza energetica e a una riduzione del costo totale di proprietà.
Miglioramento dell'Inferenza nei Grandi Modelli Linguistici (LLM)
Nel panorama dell'IA, i LLM sono essenziali per diverse applicazioni di inferenza. La H200 offre una prestazione di inferenza doppia rispetto alle GPU H100, specialmente nel gestire grandi modelli come Llama2 70B. Questo aumento della capacità di elaborazione è un fattore critico per le aziende che dipendono dall'IA per un'ampia gamma di esigenze di inferenza.
Caratteristiche Principali
- 141GB di memoria GPU HBM3e
- 4.8TB/s di larghezza di banda della memoria
- 4 petaFLOPS di prestazione FP8
- Miglioramento 2X nella prestazione di inferenza LLM
- Incremento di 110X nella prestazione HPC
Avanzamento nel Computing ad Alte Prestazioni
La H200 eccelle nelle applicazioni HPC, dove la larghezza di banda della memoria è vitale per il rapido trasferimento e l'elaborazione dei dati. Riduce significativamente il tempo per ottenere risultati in applicazioni intensive di memoria come simulazioni, ricerca scientifica e IA, offrendo prestazioni fino a 110 volte più rapide.
Efficienza Energetica e Riduzione del Costo Totale di Proprietà (TCO)
La H200 mantiene lo stesso profilo energetico della H100 ma con prestazioni notevolmente migliorate. Questo equilibrio tra potenza ed efficienza è fondamentale per le fabbriche di IA e i sistemi di supercomputing, spingendo avanti sia le comunità IA che scientifiche in modo più ecologico.
| Specification | NVIDIA H100 | NVIDIA H200 |
|---|---|---|
| Form Factor | - | H200 SXM |
| FP64 | - | 34 TFLOPS |
| FP64 Tensor Core | - | 67 TFLOPS |
| FP32 | - | 67 TFLOPS |
| TF32 Tensor Core | - | 989 TFLOPS |
| BFLOAT16 Tensor Core | - | 1,979 TFLOPS |
| FP16 Tensor Core | - | 1,979 TFLOPS |
| FP8 Tensor Core | - | 3,958 TFLOPS |
| INT8 Tensor Core | - | 3,958 TFLOPS |
| GPU Memory | 80 GB | 141 GB |
| GPU Memory Bandwidth | - | 4.8 TB/s |
| Decoders | - | 7 NVDEC, 7 JPEG |
| Max Thermal Design Power | 350 W | Up to 700W |
| Multi-Instance GPUs | - | Up to 7 MIGs @16.5GB each |
| Interconnect | PCIe 5.0 x16 | NVLink: 900GB/s, PCIe Gen5: 128GB/s |
| Server Options | - | NVIDIA HGX H200 partner and NVIDIA-Certified Systems with 4 or 8 GPUs |
| NVIDIA AI Enterprise | - | Add-on |