Nvidia Fugatto presenta il Modello Generativo avanzato per l'Audio
Utilizzando testo e audio come input, un nuovo modello di intelligenza artificiale generativa di NVIDIA può creare qualsiasi combinazione di musica, voci e suoni.

Utilizzando testo e audio come input, un innovativo modello di intelligenza artificiale generativa sviluppato da NVIDIA è in grado di creare qualsiasi combinazione di musica, voci e suoni. Questa tecnologia, denominata Fugatto, rappresenta un vero e proprio coltellino svizzero per la produzione sonora, consentendo agli utenti di controllare l'output audio attraverso semplici comandi testuali.
Sebbene altri modelli di intelligenza artificiale siano in grado di comporre brani musicali o modificare voci, nessuno possiede la flessibilità e la destrezza di Fugatto. Questo modello è capace di generare o trasformare qualsiasi combinazione di musica, voci e suoni, descritta tramite prompt che uniscono testo e file audio.
Ad esempio, Fugatto può generare una clip musicale da un semplice testo, rimuovere o aggiungere strumenti a un brano già esistente, cambiare l'accento o l'emozione di una voce, e persino creare suoni completamente nuovi mai uditi prima. “È straordinario”, afferma Ido Zmishlany, produttore multi-platino e cofondatore di One Take Audio, membro del programma NVIDIA Inception. “L'idea di poter creare nuovi suoni in tempo reale è incredibile”.
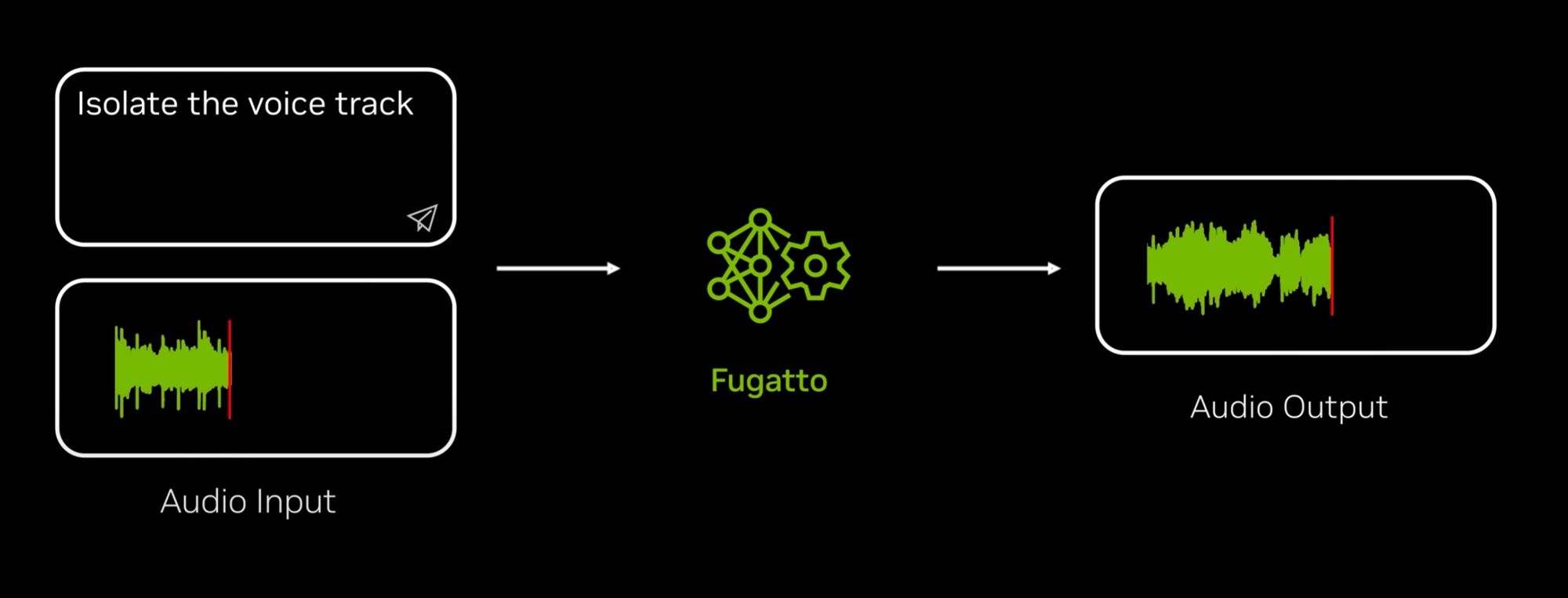
Fugatto: Approccio Innovativo alla Generazione del Suono
“Volevamo creare un modello che comprendesse e generasse suoni come fanno gli esseri umani”, ha affermato Rafael Valle, responsabile della ricerca applicata sull'audio presso NVIDIA e uno dei creatori di Fugatto. Questo modello rappresenta la prima piattaforma generativa fondazionale per l'audio, capace di combinare molteplici capacità emergenti. Fugatto utilizza istruzioni libere, consentendo agli utenti di esplorare ed esprimere la propria creatività senza restrizioni.
Fugatto rappresenta un passo fondamentale verso un futuro in cui l'apprendimento multitasking non supervisionato nella sintesi e trasformazione audio emergerà direttamente dai dati e dalla scala del modello. Produttori musicali, agenzie pubblicitarie, sviluppatori di videogiochi e molti altri possono giovare di questo strumento, utilizzandolo per prototipare rapidamente idee, creare effetti speciali o personalizzare contenuti audio per una vasta gamma di applicazioni.
L'Impatto dell'Intelligenza Artificiale sulla Musica
“La storia della musica è anche una storia di tecnologia”, continua Zmishlany. “La chitarra elettrica ha dato vita al rock and roll. Quando è stato introdotto il campionatore, è nato l'hip-hop. Con l'intelligenza artificiale, stiamo scrivendo il prossimo capitolo della musica. Abbiamo un nuovo strumento per creare musica, ed è estremamente entusiasmante”.
Fugatto permette anche di modificare accenti ed emozioni nelle voci, un'abilità particolarmente utile per personalizzare campagne pubblicitarie o creare contenuti per l'apprendimento delle lingue con voci familiari. Gli sviluppatori di videogiochi possono utilizzare il modello per adattare asset audio preregistrati, oppure creare nuovi suoni dinamicamente in base all'azione di gioco.
Generazione di Suoni Innovativi con Fugatto
Una delle caratteristiche più affascinanti di Fugatto è la sua capacità di generare suoni nuovi e inaspettati, come una tromba che abbaia o un sassofono che miagola — qualsiasi cosa gli utenti riescano a descrivere, il modello è in grado di crearla. Attraverso un fine-tuning con piccoli campioni di dati vocali, Fugatto è persino capace di generare una voce cantata di alta qualità partendo da un testo.
L'adozione della tecnica ComposableART durante l'inferenza consente a Fugatto di combinare istruzioni apprese separatamente durante l'addestramento, ad esempio generando una voce triste con accento francese. Questa capacità di interpolare tra istruzioni offre un controllo fine agli utenti, consentendo loro di regolare l'intensità dell'accento o il livello di emozione.
Inoltre, il modello genera suoni che evolvono nel tempo, come un temporale che si sposta attraverso un paesaggio con crescendo di tuoni che svaniscono gradualmente. Fugatto dà agli utenti un controllo dettagliato su come il paesaggio sonoro si sviluppa, permettendo di creare ambientazioni dinamiche e in continua evoluzione.
Architettura e Addestramento di Fugatto
Fugatto è un modello transformer generativo fondazionale, sviluppato sulla base di precedenti lavori del team nei campi della modellazione del parlato, del vocoding e della comprensione dell'audio. La versione completa del modello utilizza 2,5 miliardi di parametri ed è stata addestrata su sistemi NVIDIA DGX dotati di 32 GPU NVIDIA H100 Tensor Core.
Il progetto è stato realizzato grazie alla collaborazione di un gruppo eterogeneo di ricercatori provenienti da tutto il mondo, tra cui India, Brasile, Cina, Giordania e Corea del Sud, che hanno contribuito a rafforzare le capacità multi-accento e multilingua di Fugatto. La creazione di un dataset misto contenente milioni di campioni audio è stata una delle sfide più complesse, ma il risultato è un modello capace di eseguire compiti che superano ampiamente le aspettative.
Fugatto non si limita a replicare i dati su cui è stato addestrato, ma è in grado di creare paesaggi sonori mai sentiti prima, come un temporale che si dissolve in un'alba accompagnata dal canto degli uccelli. “Quando il team ha visto Fugatto generare musica da un semplice prompt, siamo rimasti estasiati”, ricorda Valle. E quando il modello ha creato musica elettronica con cani che abbaiavano a ritmo, “è stato un momento che ci ha fatto ridere di cuore”.
Con Fugatto, NVIDIA apre nuove possibilità per il mondo dell'audio e della musica, consentendo agli utenti di esplorare la propria creatività come mai prima d'ora.