Memory Architecture e Retrieving a Memory in Google Titans
La Memoria nelle Reti Neurali: Architettura e Recupero


L’utilizzo della memoria nelle reti neurali è un campo in continua evoluzione che mira a migliorare la capacità delle reti di memorizzare e recuperare informazioni rilevanti nel tempo. Di seguito cercherò di esplorare due concetti fondamentali nel contesto delle reti neurali, con un focus particolare sulle architetture di memoria e sul processo di recupero delle informazioni descritto dal paper Titans: Learning to Memorize at Test Time e trattato all'interno dell'altro articolo Google TITANS una nuova memoria.
Memory Architecture: Come Funziona la Memoria a Lungo Termine
La memoria a lungo termine in una rete neurale è progettata per archiviare dati utili provenienti dal passato e integrarli nel processo di inferenza futuro. Questo approccio si basa su Multi-Layer Perceptrons (MLPs) con almeno due layer (LM ≥ 2), che risultano essere significativamente più espressivi rispetto ai modelli lineari.
Perché MLPs con LM ≥ 2?
Le MLPs con due o più layer hanno una capacità maggiore di rappresentare funzioni non lineari, rendendole adatte per catturare dipendenze complesse nei dati storici. Questo è particolarmente utile quando si utilizza una matrice di memoria , che comprime i dati passati e li trasforma in una rappresentazione più compatta.
Un Approccio Matematico
Nel contesto dell’ottimizzazione, una matrice di memoria viene trattata come una soluzione per minimizzare un obiettivo di regressione lineare online. L’ottimizzazione minimizza l’errore quadratico tra i dati osservati e il contenuto memorizzato, rendendo la dipendenza storica dei dati una funzione lineare. Tuttavia, grazie alla profondità e non linearità delle MLPs, queste architetture possono rappresentare relazioni più complesse rispetto a quelle ottenute con approcci lineari.
Vantaggi di Architetture Avanzate
Recenti lavori di ricerca hanno dimostrato che l’uso di memorie profonde (“deep memory modules”) è più efficace in contesti pratici. Incorporando queste architetture nel framework esistente, le reti possono migliorare notevolmente la loro capacità di ricordare e utilizzare informazioni passate in modo strategico.
Retrieving a Memory: Come Recuperare le Informazioni
Uno degli aspetti più importanti della memoria nelle reti neurali è la capacità di recuperare informazioni rilevanti senza aggiornare i pesi del modello durante l’inferenza. Questo processo si basa su una pipeline chiara:
- Proiezione dell’input:L’input corrente viene proiettato in uno spazio latente tramite una matrice lineare . Questo genera una query , che è una rappresentazione compatta dell’input.
- Recupero dalla memoria:La query viene utilizzata per interrogare la memoria . La memoria restituisce un’informazione utile , calcolata come: dove rappresenta il modulo di memoria ottimizzato per recuperare informazioni rilevanti.
Esempio Pratico
Immaginiamo un sistema di traduzione automatica che apprende da conversazioni precedenti. Durante l’inferenza, il sistema usa la query per recuperare strutture linguistiche o vocaboli rilevanti dalla memoria, migliorando la qualità della traduzione senza bisogno di riaddestrare il modello in tempo reale.
Il Ruolo delle tecnologie avanzate come Titans
Progetti come Google Titans rappresentano un punto di riferimento nell’implementazione di architetture di memoria su larga scala. Titans utilizza una combinazione di:
- Memorie avanzate basate su MLPs: Queste memorie riescono a catturare dipendenze complesse nei dati.
- Tecniche di compressione e recupero ottimizzate: Questi approcci riducono il costo computazionale, garantendo al contempo un recupero rapido e accurato delle informazioni.
Long-term Memory
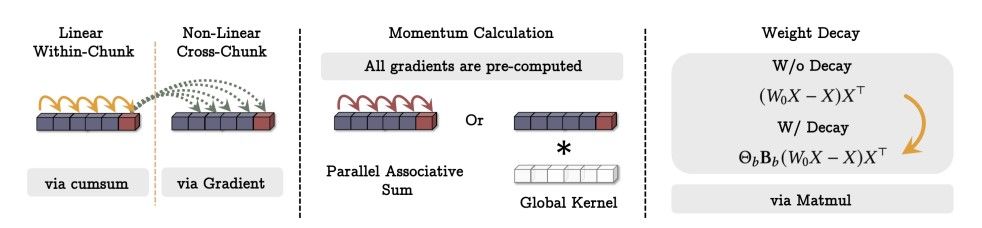
1. Linear Within-Chunk
In questa fase, i dati all'interno di un chunk (o blocco) vengono elaborati linearmente. Ogni elemento del chunk influenza i successivi attraverso operazioni cumulative.
Tecnica: Utilizzo di una funzione di somma cumulativa (“cumsum”).
Obiettivo: Integrare relazioni sequenziali tra i dati all'interno dello stesso blocco.
2. Non-Linear Cross-Chunk
Qui le relazioni non lineari tra i dati di chunk differenti vengono elaborate.
Tecnica: Si utilizza il gradiente per aggiornare i pesi o i valori associati ai dati nei vari chunk.
Obiettivo: Catturare dipendenze complesse tra blocchi di dati, andando oltre la semplice linearità.
3. Momentum Calculation
Questa fase calcola il momentum per aggiornare i pesi basandosi sui gradienti.
Opzioni:
- Parallel Associative Sum: Somma parallela di tutti i gradienti pre-computati.
- Global Kernel: Utilizzo di un kernel globale per catturare pattern su larga scala.
Obiettivo: Ottimizzare il processo di addestramento migliorando la convergenza attraverso l'uso del momentum.
4. Weight Decay
La tecnica di Weight Decay penalizza i pesi per prevenire l'overfitting, modificando l'aggiornamento dei pesi attraverso una moltiplicazione con matrici.
Formule:
- Senza Decadimento:
(W0 X - X) XT - Con Decadimento:
Θb Bb (W0 X - X) XT
Obiettivo: Ridurre l’importanza di pesi eccessivi per evitare che il modello si adatti troppo ai dati di addestramento.
L'immagine evidenzia un approccio scalabile e parallelo per addestrare una memoria neurale.
Tecniche principali: Somma cumulativa, calcolo del gradiente, momentum parallelo, kernel globale, e decadimento dei pesi.
Efficienza: L'uso di matrici (“matmuls”) permette di velocizzare il calcolo, rendendo il processo computazionalmente praticabile su larga scala.