La pasta italiana AI con OpenVINO su Edge Hardware
Follow the article, in the next few hours I will publish all the code updates.


Il modello AI è stato allenato per riconoscere i diversi formati di pasta italiana. All'interno di questa ricerca vengono descritti tutti i passaggi e gli strumenti utilizzati per la creazione del modello e del codice.
Su GitHub trovi tutto il codice sorgente.
Creazione del dataset
La creazione del modello è basata su 5 formati di pasta italiana (conchiglie, ditalini, fusilli, farfalle, sedani).


Ecco alcuni strumenti molto utile e veloci per la creazione del label : edgeimpulse.com e darwin.v7labs.com. Alla Fine di questo articolo ho aggiunto una lista di alcuni Data Labeling Platform interessanti che possono essere utilizzate in modo gratuito o con un ampio livello free:
Per la creazione del modello sono state utilizzate 375 immagini divisi in 5 gruppi, utilizzando 80% dataset train e 20% in test.
I dati di addestramento vengono utilizzati per addestrare il modello, mentre i dati di test servono per verificare l'accuratezza del modello dopo l'addestramento. È consigliato un rapporto di suddivisione approssimativo di 80/20 tra addestramento e test per i dati, per ogni classe (o etichetta) nel dataset, sebbene dataset particolarmente grandi possano richiedere meno dati di test.

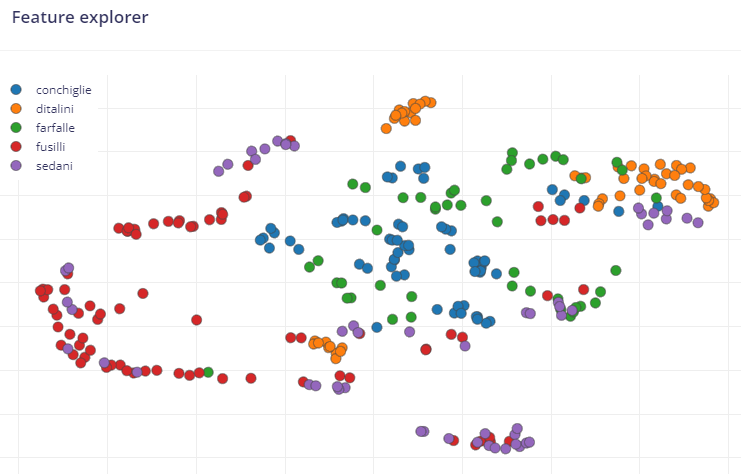
Creazione del modello
Confronta le prestazioni di addestramento delle varianti ottimizzate del modello. È possibile scegliere un'ottimizzazione durante la distribuzione.
Da questi dati sono stati generati tre modelli in modo da poter confrontare le singole performance:
- Il primo FOMO (Faster Objects, More Objects) MobileNetV2 0.1 , un modello di rilevamento degli oggetti basato su MobileNetV2 (alpha 0.1) progettato per segmentare grossolanamente un'immagine in una griglia di sfondo rispetto a oggetti di interesse. Questi modelli sono progettati per avere una dimensione inferiore a 100KB e supportano un ingresso in scala di grigi o RGB a qualsiasi risoluzione.
- Il secondo modello usa YOLOv5 un modello di apprendimento basato su Ultralytics YOLOv5 , che viene trasferito utilizzando i pesi yolov5n.pt. Esso supporta l'input RGB a qualsiasi risoluzione, ma è limitato a immagini quadrate.
- Il terzo modello, poi utilizzato, è stato fatto usando un dataset in formato Darwin 2.0 (JSON) e mediante PyTorch e poi ottimizzato con OpenVINO.
Risultati del test fatto su i modelli
I risultati ottenuti dal test sono abbastanza buoni con un livello di accuracy oltre 88%, dove si evidenzia un livello di carenza dei dati relativi a solo due tipologie di pasta (sedani e fusilli).
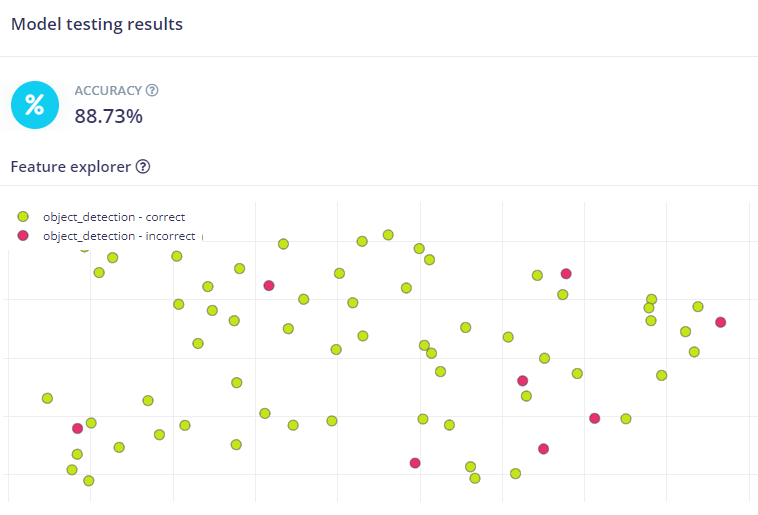
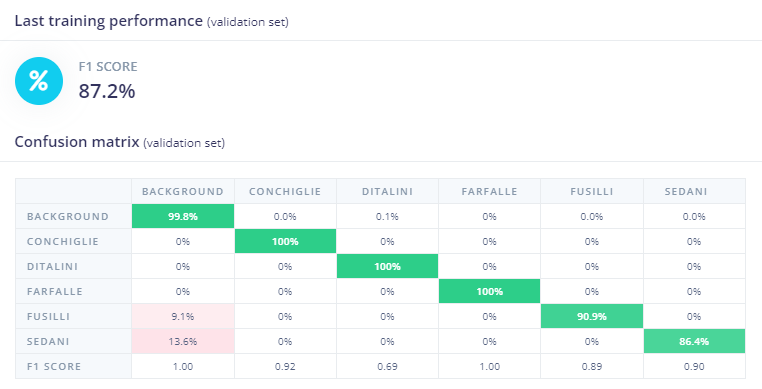
Applicazione pratica e codice python
L'applicazione in esempio effettua il riconoscimento mediante una webcam live dei diversi tipi di pasta in diversi contesti, oltre a classificare conta il quantitativo individuando il peso.
Caratteristiche dell'applicazione:
- Classificazione tipi di pasta
- Conteggio numero per tipo
- Calcolo peso approssimato
(Codice in scrittura ... aggiungi tra i preferiti questa pagina e ritorna tra qualche ora).
Data Labeling Platform
Le Data Labeling Platform, o piattaforme di etichettatura dei dati, sono sistemi software utilizzati per annotare e classificare i dati, in particolare per scopi di apprendimento automatico e intelligenza artificiale. Queste piattaforme consentono agli utenti di etichettare grandi quantità di dati, come immagini, testi, file audio o video, assegnando loro etichette o categorie specifiche.
Questa etichettatura è fondamentale nel processo di apprendimento supervisionato, dove il modello di apprendimento automatico impara da un set di dati precedentemente etichettato per fare previsioni o classificazioni su nuovi dati. Le etichette fungono da guida per il modello, indicando cosa è presente nei dati o quale comportamento si sta cercando di predire.
Ecco una lista di alcuni Data labeling Platform interessanti:
 cvat-ai
cvat-ai


.png)


