FLUX.1 Kontext
Verso una piattaforma integrata per la generazione e l’editing semantico di immagini

FLUX.1 Kontext, sviluppato da Black Forest Labs, rappresenta un contributo rilevante all'evoluzione dei modelli generativi per la sintesi e l’editing di immagini nel dominio latente. La sua architettura sfrutta un approccio di flow matching rettificato all'interno di uno spazio latente appreso, offrendo una piattaforma unificata in grado di supportare sia la generazione ex novo che la modifica condizionata su immagini di riferimento. Rispetto agli approcci autoregressivi e ai tradizionali modelli di diffusione, FLUX.1 Kontext mostra una marcata efficienza computazionale e una robustezza semantica che lo rendono adatto a task iterativi e a flussi di lavoro interattivi.

Architettura e metodologia
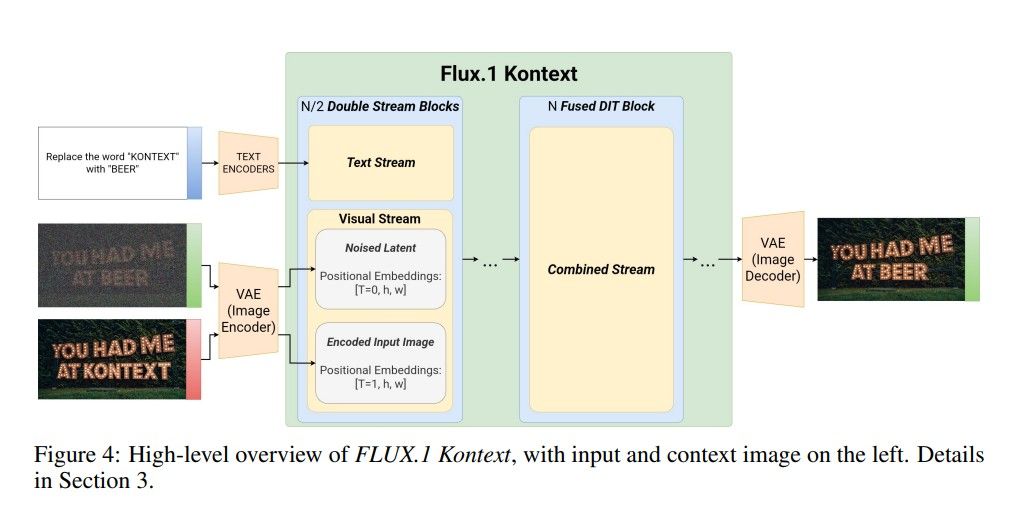
Il modello si fonda su un rectified flow transformer, addestrato su rappresentazioni latenti prodotte da un autoencoder convoluzionale ottimizzato con obiettivi avversariali. A differenza di pipeline che operano nello spazio dei pixel, FLUX.1 Kontext agisce interamente nello spazio latente, riducendo la dimensionalità del problema e migliorando la coerenza semantica nelle operazioni di trasformazione. L’architettura impiega blocchi misti double-stream e single-stream: i primi gestiscono separatamente token visivi e testuali, mentre i secondi operano esclusivamente sui token visivi.
Il modello utilizza una semplice concatenazione sequenziale per codificare contesti visivi e istruzioni testuali, abilitando una generalizzazione fluida tra editing locale (y ≠ ∅) e generazione libera (y = ∅). Le informazioni posizionali sono codificate tramite Rotary Positional Embeddings in uno spazio tridimensionale (t, h, w), dove il tempo virtuale t consente di separare gerarchicamente contesto e target all’interno della sequenza.
Prestazioni empiriche e benchmark
FLUX.1 Kontext è stato valutato attraverso KontextBench, un dataset di 1026 coppie immagine-prompt distribuite su cinque categorie: editing locale, editing globale, riferimenti stilistici, riferimenti a personaggi e modifiche testuali. I risultati dimostrano un'elevata qualità generativa sia nei task single-turn che multi-turn, con una significativa riduzione del fenomeno del drift semantico. Il modello raggiunge latenze di inferenza comprese tra 3 e 5 secondi per immagini 1024x1024, rendendolo compatibile con scenari applicativi interattivi.
FLUX.1 Kontext mostra inoltre superiorità nella conservazione delle caratteristiche identitarie di soggetti visivi rispetto a modelli concorrenti, come GPT-Image o Runway Gen-4, come confermato dall’analisi su metriche di similarità facciale (AuraFace). Queste prestazioni lo posizionano tra i modelli più competitivi nel contesto dell’editing iterativo e della generazione condizionata ad alta fedeltà.
Applicazioni avanzate e casi d’uso
Oltre alle funzionalità di editing standard, FLUX.1 Kontext supporta una gamma di operazioni avanzate che includono:
- Style reference: trasferimento dello stile visivo di un'immagine di input verso scene semantiche differenti, con mantenimento delle caratteristiche artistiche.
- Product-centric editing: generazione e modifica di varianti di prodotti in ambienti controllati, utile in ambiti come l'e-commerce e il design industriale.
- Visual cue processing: interpretazione di input visivi (es. bounding box o marcature grafiche) per guidare l'editing secondo vincoli spaziali definiti dall’utente.
- Text-region editing: intervento sulle regioni testuali presenti nell'immagine, come titoli, logotipi e contenuti descrittivi, mantenendo coerenza tipografica e contestuale.
Tali capacità, unite a un'infrastruttura di inferenza rapida, ne favoriscono l'integrazione in pipeline creative e sistemi di content generation professionale.

Limiti e prospettive di sviluppo
Nonostante i risultati promettenti, FLUX.1 Kontext presenta alcune limitazioni operative:
- In contesti di editing prolungato su più turni, si possono verificare artefatti visivi e perdita di fedeltà rispetto alla distribuzione iniziale.
- L'aderenza alle istruzioni testuali può risultare imprecisa in caso di prompt ambigui o compositi.
- La conoscenza implicita del modello è limitata alla distribuzione dei dati di addestramento, riducendo la capacità di generare contenuti fortemente ancorati al mondo reale.
Gli autori propongono varie linee di sviluppo future, tra cui:
- Estensione del contesto multimodale a sequenze di immagini o a dati video;
- Integrazione con pipeline neurali a basso consumo per abilitare l’inferenza edge;
- Riduzione della degradazione semantica in sessioni iterative attraverso modelli di stabilizzazione.
Leggi tutte le informazioni tecniche nel PDF:
FLUX.1 Kontext: Flow Matching for In-Context Image Generation and Editing in Latent Space
